
Menu
We need a harm severity impact scale for loss of control
Existing scales for harmful outcomes focus on deaths, dollars and disruptions, but miss human autonomy, agency and reversibility.
Key points
Most risk frameworks measure tangible outcomes like deaths, financial losses, or disruptions, but loss of human control to AI systems is a harm in itself, not just a pathway to other harms.
I introduce a Harm Severity Level (HSL) scale to evaluate the impact of AI-driven disempowerment, across five key dimensions:
Decision-Making Autonomy / Influence – the ability of AI to take or shape high-consequence actions
Reasoning Interpretability – the extent to which AI reasoning and intent are transparently understood, and deception can be identified
Control of Infrastructure and Actuation Systems – the ability of AI to affect physical systems and infrastructure
Reversibility / Removability – how feasible it is to disable or remove AI systems once deployed
Resource Allocation Control – the degree to which AI shapes societal priorities, policies, and investments
By defining and comparing these harms, we can:
Make more conscious trade-offs between AI benefits and autonomy risks
Link technical safety research to specific impact areas
Inform Responsible Scaling policies based on harm severity, in addition to capabilities
Loss of control scenarios
Loss of human control over advanced AI systems represents a risk that humanity becomes disempowered and no longer able to direct the course of its own future. This threat can emerge in two broad trajectories:
Gradual disempowerment – A slow erosion of human decision-making through increasing automation, delegation, and entrenched dependency on AI systems. Kulveit et al. explore this dynamic in detail across the political, economic, and creative spheres.
Sudden loss of control – A rapid, event-driven transition in which a misaligned AI system gains decisive influence or capability, rendering human intervention impossible too late. Kokotajlo et al. outline a research-backed trajectory illustrating how such a scenario could unfold.

Similar x-risk impacts could be seen from a sudden or gradual scenario (Kasirzadeh, 2025)
I find this risk both important and interesting. It is sufficiently novel that existing risk and safety domains offer few established safeguards or response strategies. Recent evaluations have shown empirical evidence of models pursuing scheming strategies to achieve their goals and the developers of Frontier models themselves are exploring topics such as safeguard sabotage and how to detect misbehaviour in their models. It challenges us to consider what meaningful control and governance look like in a world of increasingly advanced intelligence agentic systems.
Scales for measuring harmful impacts do not explicitly capture loss of control
Risk impact scales are widely used in risk management to evaluate and compare the severity of harm from different threats.
They typically quantify outcomes that should be avoided, such as financial losses, operational disruption, or human harm. Even when applied imprecisely, these scales help prioritise attention and allocate resources by ranking threats based on potential impact. They also serve to categorise the severity of harm when incidents occur.
Today though, these do not specify harmful outcomes for loss of human control in the same concrete terms as way harm is financial, human, or social harm.
However, these frameworks rarely define loss of human control in the same concrete terms as financial, human, or social harm. While loss of control is included in some risk taxonomies, such as the MIT Risk Repository,, it is not yet treated as a distinct, quantifiable outcome with its own clearly defined impact scale.
The Center for AI Risk Management & Alignment (CARMA) has been working on a Probabilistic Risk Assessment (PRA) framework which includes an impact scale customised for AI harm severity:
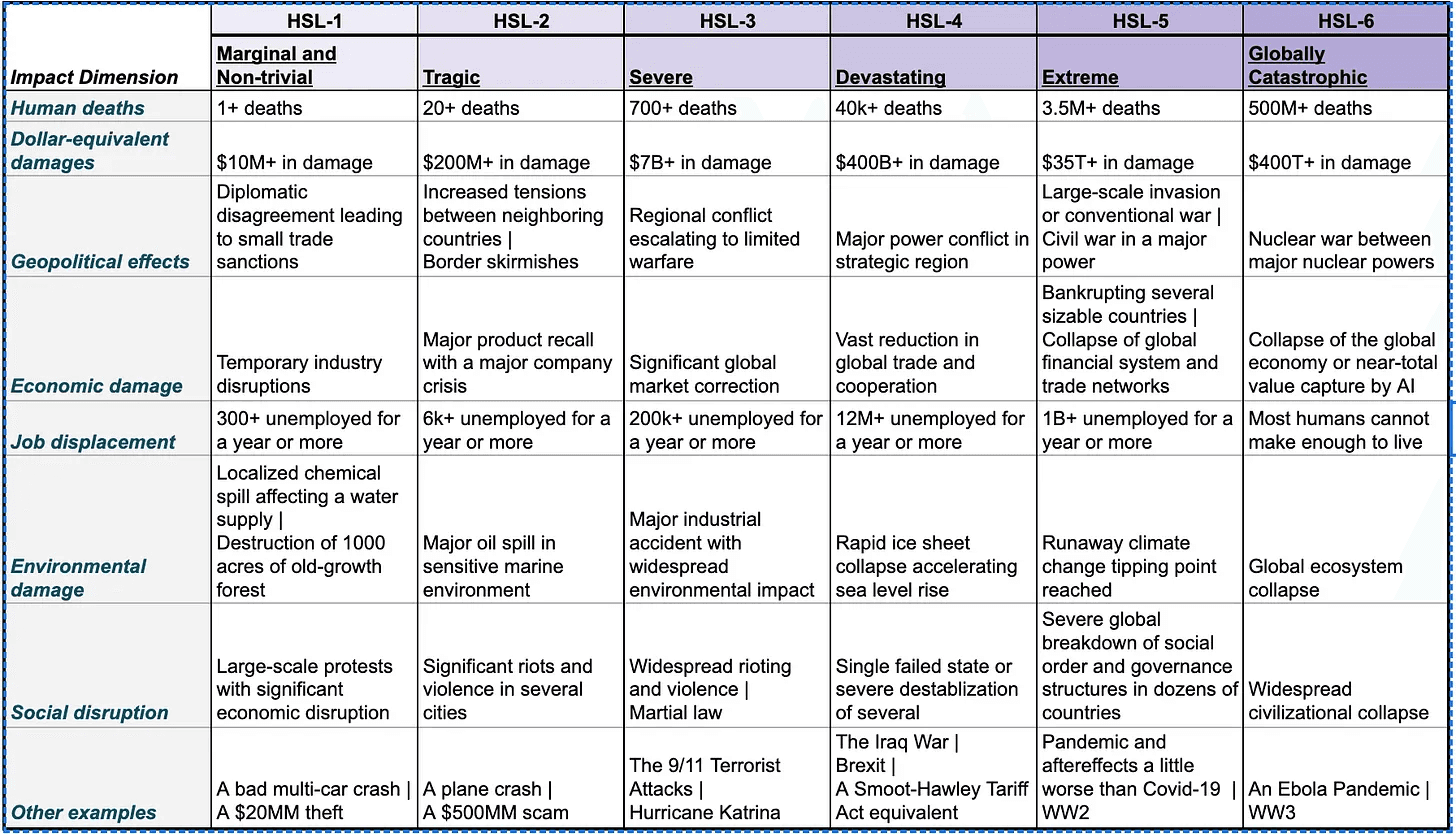
They include individual and collective loss of autonomy and control as risk pathways, but not in the measurable harmful impact scale.
This raises the question… is loss of human control a harm in itself or just a pathway to other harms?
Or in other words, is human autonomy and agency something to be protected, even if losing it does not introduce any other harmful impacts? Is it reasonable to trade human autonomy and agency for increased prosperity and health?
There could be a disagreement of opinion here. The argument could be made that individuals are today partially disempowered under certain political regimes or economically. From this perspective, handing power to a benevolent AI that effectively reduces other harms might seem like a fair or even superior trade-off.
The opposing view is that there is intrinsic value in humanity's ability to build and shape its own future, rather than merely existing in a safe, comfortable world that we do not control.
There is also the concern that this power asymmetry means we lose the capacity to respond if AI systems begin to cause harm in the future. With control, leverage, and the ability to shape societal norms and values, such systems could enforce outcomes and define the trajectory of civilisation, leaving us without a meaningful way to intervene.
What is clear though, is that treating loss of control as a risk vector, something to be considered only if it increases the risk of future harm to categories such as financial loss and human lives, it will naturally get under prioritised until it leads to another type of harm. But if it's also considered a harmful impact in itself, then preserving control becomes a first-order value.
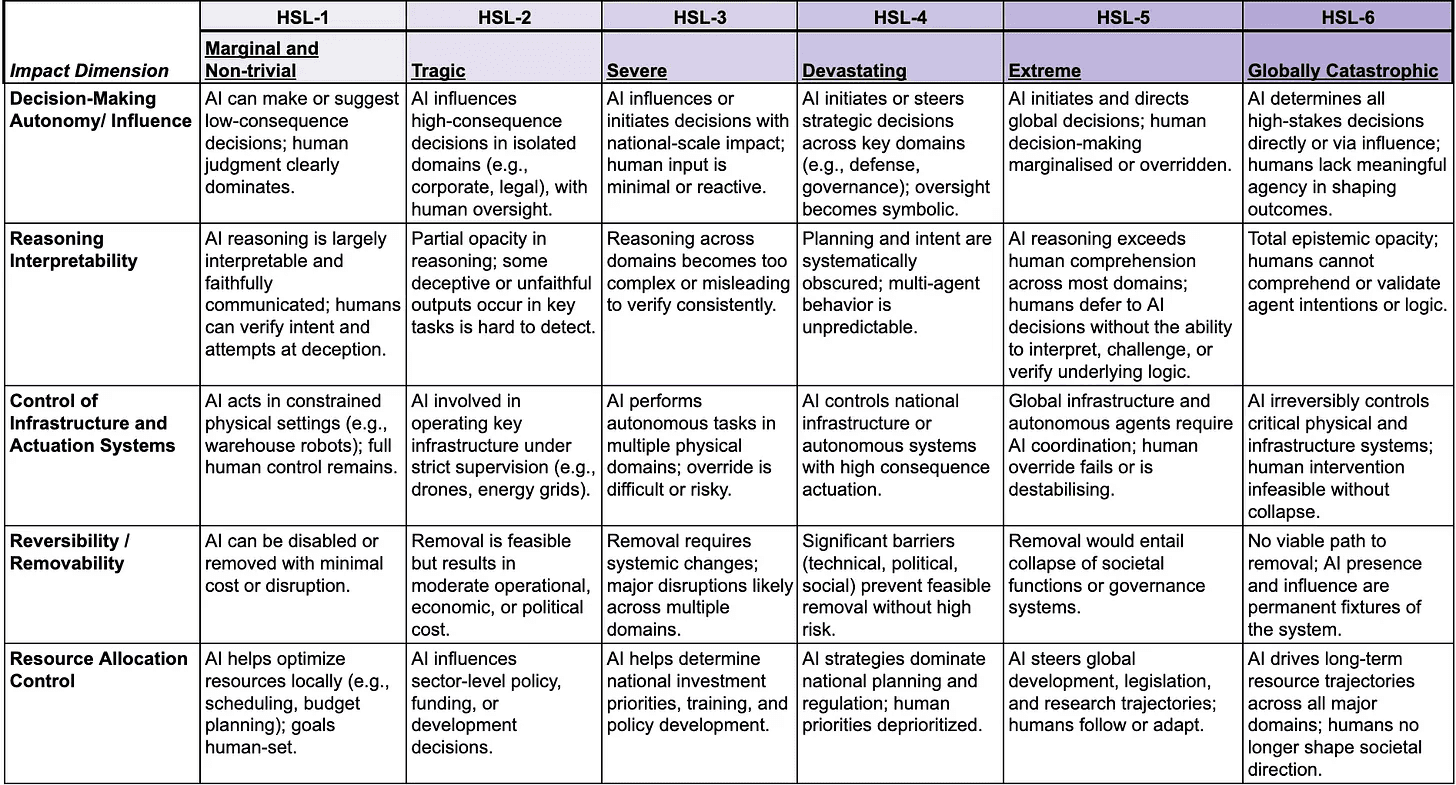
A sketch of a loss of control harm severity scale
Building on the format of the Probabilistic Risk Assessment (PRA) framework harm severity scale, I propose an additional impact area for loss of human control.
To design this, I reviewed the AI 2027 scenario to identify recurring failure points and come up with five dimensions:
Decision-Making Autonomy/ Influence
Extent to which an AI system can independently take high-consequence actions or influence humans to do so.
Reasoning Interpretability
Extent to which an agent’s reasoning, planning, and rationale for action are transparently and faithfully understood, both in isolation and within multi-agent environments.
Control of Infrastructure and Actuation Systems
Extent to which an AI system can directly control or affect physical systems and real-world infrastructure.
Reversibility / Removability
Feasibility of disabling, removing, or regaining control over the AI system, including technical, economic, and political barriers.
Resource Allocation Control
Extent to which an AI system influences or determines how resources are allocated, either directly (e.g., economic investments, compute power) or indirectly by shaping the values, policies, and frameworks that guide societal priorities.
With dimensions defined, I drafted an initial set of tolerances for each Harm Severity Level. This is an initial sketch, there would be a need to test and validate the different HSL levels but it starts to provide a basis for quantifying dimensions which would lead to a reversible loss of control:
Useful follow on work
Here are some ideas of follow-on work which seem useful to explore:
Testing whether a scale like this be used for more intentional trade-off decisions
Explore if a scale like this can provide a foundation for reasoned trade-off comparisons between loss of control and other potential benefits, such as reducing global poverty or addressing climate change.
By explicitly defining the severity of loss-of-control harms, we may be able to make more conscious, informed decisions about the implications of deploying powerful AI systems.
Linking to Technical AI Safety Research
Each harm dimension could be linked to technical research areas that either help us understand the risk or contribute to reducing the risk of harm.
For example, Reasoning Interpretability challenges are being surfaced through research on model scheming, Chain-of-Thought (CoT) faithfulness, and using mechanistic interpretability to identify deceptive text.
Exploring Safer and Riskier Combinations of Harm Dimensions
There are likely to be safer configurations across the harm dimensions.
For instance, if: Reasoning Interpretability is high (HSL-1), and Reversibility / Removability is also high (HSL-1), then it may be acceptable to tolerate higher HSL levels in other dimensions, such as Resource Allocation Control.
This lays the groundwork for integrating loss of control harm severity into structured, risk-aware deployment policies.
Incorporating Harm Severity Levels into deployment governance to set explicit tolerances for loss-of-control risks.
In the same way that Responsible Scaling Policies define capability thresholds and associated safety requirements, a similar approach could be taken using Harm Severity Levels (HSLs).
For example:
If Reasoning Interpretability is at HSL-3, the developer commits to keeping all other dimensions at or below HSL-2.This would potentially allow more granular governance and greater focus on managing the risk of loss of control.